Chapter 2 Intelligent Agents
2.1 Agents and Environments
An agent is anything that can be viewed as perceiving its environment through sensors and acting upon that environment through actuators.

We use the term percept to refer to the content an agent’s sensors are perceiving. An agent’s percept sequence is the complete history of everything the agent has ever perceived. In general, an agent’s choice of action at any given instant can depend on its built-in knowledge and on the entire percept sequence observed to date, but not on anything it hasn’t perceived. Mathematically speaking, we say that an agent’s behavior is described by the agent function that maps any given percept sequence to an action.
Internally, the agent function for an artificial agent will be implemented by an agent program. It is important to keep these two ideas distinct. The agent function is an abstract mathematical description; the agent program is a concrete implementation, running within some physical system.
2.2 Good Behavior: The Concept of Rationality
A rational agent is one that does the right thing.
2.2.1 Performance measures
Moral philosophy has developed several different notions of the “right thing,” but AI has generally stuck to one notion called consequentialism: we evaluate an agent’s behavior by its consequences.
This notion of desirability is captured by a performance measure that evaluates any given sequence of environment states.
2.2.2 Rationality
What is rational at any given time depends on four things:
The performance measure that defines the criterion of success.
The agent’s prior knowledge of the environment.
The actions that the agent can perform.
The agent’s percept sequence to date.
Definition of a rational agent: For each possible percept sequence, a rational agent should select an action that is expected to maximize its performance measure, given the evidence provided by the percept sequence and whatever built-in knowledge the agent has.
2.2.3 Omniscience, learning, and autonomy
We need to be careful to distinguish between rationality and omniscience. An omniscient agent knows the actual outcome of its actions and can act accordingly; but omniscience is impossible in reality.
Rationality maximizes expected performance, while perfection maximizes actual performance.
Doing actions in order to modify future percepts—sometimes called information gathering. Our definition requires a rational agent not only to gather information but also to learn as much as possible from what it perceives.
To the extent that an agent relies on the prior knowledge of its designer rather than on its own percepts and learning processes, we say that the agent lacks autonomy. A rational agent should be autonomous—it should learn what it can to compensate for partial or incorrect prior knowledge.
2.3 The Nature of Environments
2.3.1 Specifying the task environment
The task environment is composed of PEAS (Performance, Environment, Actuators, Sensors).
2.3.2 Properties of task environments
FULLY OBSERVABLE VS. PARTIALLY OBSERVABLE: If an agent’s sensors give it access to the complete state of the environment at each point in time, then we say that the task environment is fully observable. An environment might be partially observable because of noisy and inaccurate sensors or because parts of the state are simply missing from the sensor data. If the agent has no sensors at all then the environment is unobservable.
SINGLE-AGENT VS. MULTIAGENT: The agent-design problems in multiagent environments are often quite different from those in single-agent environments.
DETERMINISTIC VS. NONDETERMINISTIC: If the next state of the environment is completely determined by the current state and the action executed by the agent(s), then we say the environment is deterministic; otherwise, it is nondeterministic.
EPISODIC VS. SEQUENTIAL: In an episodic task environment, the agent’s experience is divided into atomic episodes. Crucially, the next episode does not depend on the actions taken in previous episodes. In sequential environments, on the other hand, the current decision could affect all future decisions.
STATIC VS. DYNAMIC: If the environment can change while an agent is deliberating, then we say the environment is dynamic for that agent; otherwise, it is static. If the environment itself does not change with the passage of time but the agent’s performance score does, then we say the environment is semidynamic.
DISCRETE VS. CONTINUOUS: The discrete/continuous distinction applies to the state of the environment, to the way time is handled, and to the percepts and actions of the agent.
KNOWN VS. UNKNOWN: In a known environment, the outcomes (or outcome probabilities if the environment is nondeterministic) for all actions are given. Obviously, if the environment is unknown, the agent will have to learn how it works in order to make good decisions.
The performance measure itself may be unknown, either because the designer is not sure how to write it down correctly or because the ultimate user—whose preferences matter—is not known. The hardest case is partially observable, multiagent, nondeterministic, sequential, dynamic, continuous, and unknown.
2.4 The Structure of Agents
The job of AI is to design an agent program that implements the agent function—the mapping from percepts to actions. We assume this program will run on some sort of computing device with physical sensors and actuators—we call this the agent architecture:
agent = architecture + program.
2.4.1 Agent programs

The daunting size of these tables means that (a) no physical agent in this universe will have the space to store the table; (b) the designer would not have time to create the table; and (c) no agent could ever learn all the right table entries from its experience.
The key challenge for AI is to find out how to write programs that, to the extent possible, produce rational behavior from a smallish program rather than from a vast table.
2.4.2 Simple reflex Agents
The simplest kind of agent is the simple reflex agent. These agents select actions on the basis of the current percept, ignoring the rest of the percept history.

A more general and flexible approach is first to build a general-purpose interpreter for condition–action rules and then to create rule sets for specific task environments.


The agent in Figure 2.10 will work only if the correct decision can be made on the basis of just the current percept—that is, only if the environment is fully observable. Even a little bit of unobservability can cause serious trouble. Infinite loops are often unavoidable for simple reflex agents operating in partially observable environments. Escape from infinite loops is possible if the agent can randomize its actions.
2.4.3 Model-based reflex agents
The most effective way to handle partial observability is for the agent to keep track of the part of the world it can’t see now. That is, the agent should maintain some sort of internal state that depends on the percept history and thereby reflects at least some of the unobserved aspects of the current state.
Updating this internal state information as time goes by requires two kinds of knowledge to be encoded in the agent program in some form. First, we need some information about how the world changes over time, which can be divided roughly into two parts: the effects of the agent’s actions and how the world evolves independently of the agent. This knowledge about “how the world works”—whether implemented in simple Boolean circuits or in complete scientific theories—is called a transition model of the world. Second, we need some information about how the state of the world is reflected in the agent’s percepts. This kind of knowledge is called a sensor model.
An agent that uses such models is called a model-based agent.


2.4.4 Goal-based agents
As well as a current state description, the agent needs some sort of goal information that describes situations that are desirable. The agent program can combine this with the model (the same information as was used in the model-based reflex agent) to choose actions that achieve the goal.
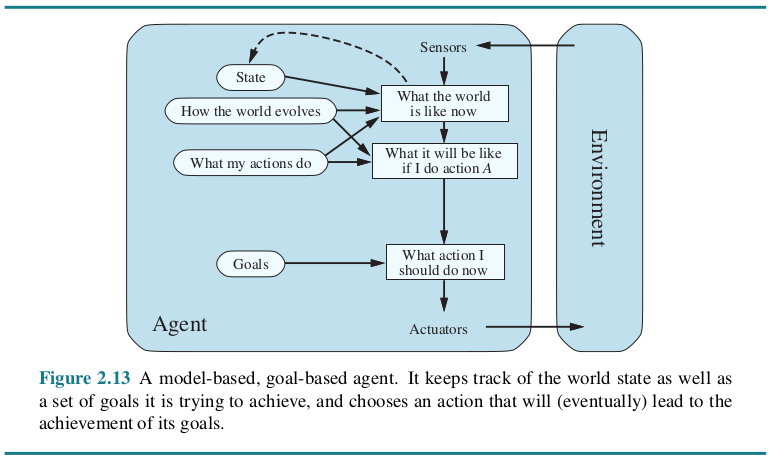
Search and planning are the subfields of AI devoted to finding action sequences that achieve the agent’s goals.
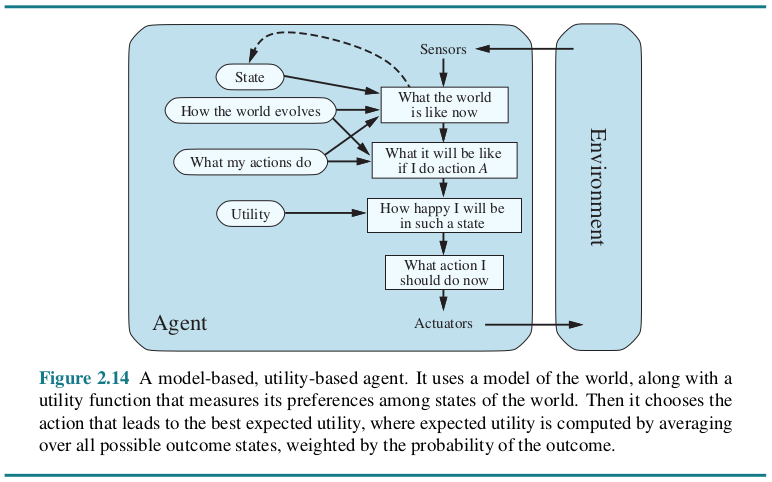
2.4.5 Utility-based agents
An agent’s utility function is essentially an internalization of the performance measure. Provided that the internal utility function and the external performance measure are in agreement, an agent that chooses actions to maximize its utility will be rational according to the external performance measure.
A rational utility-based agent chooses the action that maximizes the expected utility of the action outcomes—that is, the utility the agent expects to derive, on average, given the probabilities and utilities of each outcome.
A model-free agent can learn what action is best in a particular situation without ever learning exactly how that action changes the environment.
2.4.6 Learning agents
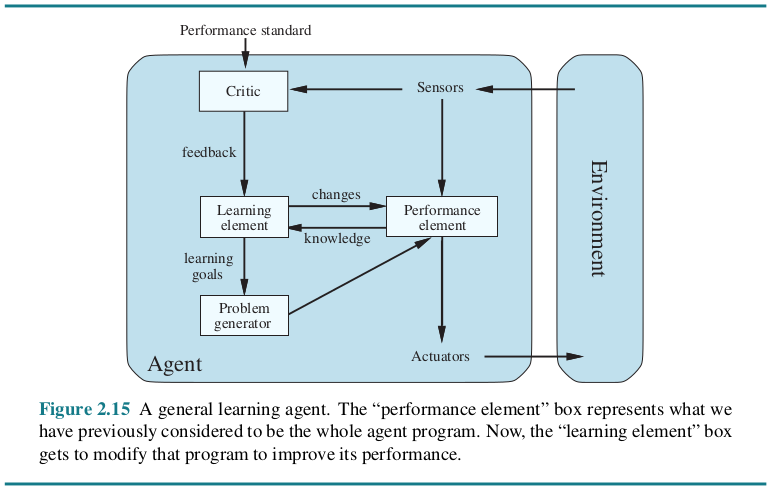
A learning agent can be divided into four conceptual components. The most important distinction is between the learning element, which is responsible for making improvements, and the performance element, which is responsible for selecting external actions. The performance element is what we have previously considered to be the entire agent: it takes in percepts and decides on actions. The learning element uses feedback from the critic on how the agent is doing and determines how the performance element should be modified to do better in the future.
The design of the learning element depends very much on the design of the performance element. Given a design for the performance element, learning mechanisms can be constructed to improve every part of the agent.
The critic tells the learning element how well the agent is doing with respect to a fixed performance standard. The critic is necessary because the percepts themselves provide no indication of the agent’s success. It is important that the performance standard be fixed.
The last component of the learning agent is the problem generator. It is responsible for suggesting actions that will lead to new and informative experiences.
Improving the model components of a model-based agent so that they conform better with reality is almost always a good idea, regardless of the external performance standard. In a sense, the performance standard distinguishes part of the incoming percept as a reward (or penalty) that provides direct feedback on the quality of the agent’s behavior. More generally, human choices can provide information about human preferences.
Learning in intelligent agents can be summarized as a process of modification of each component of the agent to bring the components into closer agreement with the available feedback information, thereby improving the overall performance of the agent.
2.4.7 How the components of agent programs work
Roughly speaking, we can place the representations along an axis of increasing complexity and expressive power—atomic, factored, and structured.
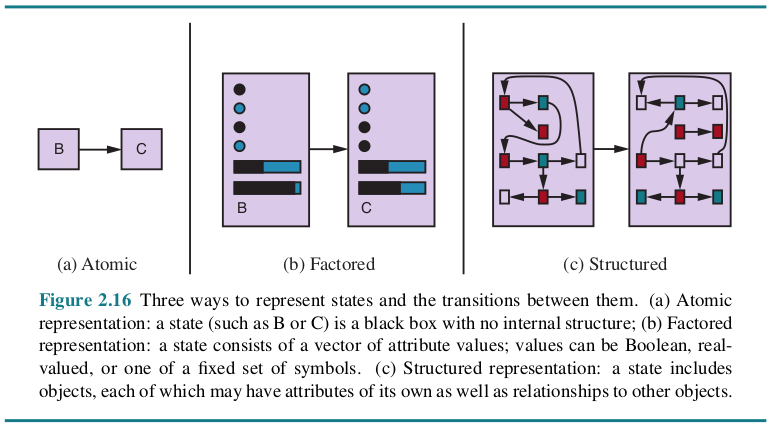
In an atomic representation each state of the world is indivisible—it has no internal structure. The standard algorithms underlying search and game-playing, hidden Markov models, and Markov decision processes all work with atomic representations.
A factored representation splits up each state into a fixed set of variables or attributes, each of which can have a value. Many important areas of AI are based on factored representations, including constraint satisfaction algorithms, propositional logic, planning, Bayesian networks, and various machine learning algorithms.
In a Structured representation, objects and their various and varying relationships can be described explicitly. Structured representations underlie relational databases and first-order logic, first-order probability models, and much of natural language understanding.
The axis along which atomic, factored, and structured representations lie is the axis of increasing expressiveness. Roughly speaking, a more expressive representation can capture, at least as concisely, everything a less expressive one can capture, plus some more.
Another axis for representation involves the mapping of concepts to locations in physical memory, whether in a computer or in a brain. If there is a one-to-one mapping between concepts and memory locations, we call that a localist representation. On the other hand, if the representation of a concept is spread over many memory locations, and each memory location is employed as part of the representation of multiple different concepts, we call that a distributed representation. Distributed representations are more robust against noise and information loss.